共役勾配法
共役勾配法(きょうやくこうばいほう、英: conjugate gradient method、CG法とも呼ばれる)は対称正定値行列を係数とする連立一次方程式を解くためのアルゴリズムである[1][2][3][4]。反復法として利用され[1][2][3][4]、コレスキー分解のような直接法では大きすぎて取り扱えない、大規模な疎行列を解くために利用される。そのような問題は偏微分方程式などを数値的に解く際に常に現れる[1][5][6][7]。
共役勾配法は、エネルギー最小化などの最適化問題を解くために用いることもできる[8][9][10]。
双共役勾配法(英語版)は、共役勾配法の非対称問題への拡張である[11]。また、非線形問題を解くために、さまざまな非線形共役勾配法が提案されている[12][13][14]。
詳説
対称正定値行列Aを係数とするn元連立一次方程式
Ax = b
の解をx*とする。
直接法としての共役勾配法
非零ベクトルu、vが

を満たすとき、u、vはAに関して共役であるという[2][3][4]。Aは対称正定値なので、左辺から内積

を定義することができる。この内積に関して2つのベクトルが直交するなら、それらのベクトルは互いに共役である。 この関係は対称で、uがvに対して共役なら、vもuに対して共役である(この場合の「共役」は複素共役と無関係であることに注意)。
{pk}をn個の互いに共役なベクトル列とする。pkは基底Rnを構成するので、Ax = bの解x*をこの基底で展開すると、

と書ける。ただし係数は



で与えられる。
この結果は、上で定義した内積を考えるのが最も分かりやすいと思われる。
以上から、Ax = bを解くための方法が得られる。すなわち、まずn個の共役な方向を見つけ、それから係数αkを計算すればよい。
反復法としての共役勾配法
共役なベクトル列pkを注意深く選ぶことにより、一部のベクトルからx*の良い近似を得られる可能性がある。そこで、共役勾配法を反復法として利用することを考える[2][3][4]。こうすることで、nが非常に大きく、直接法では解くのに時間がかかりすぎるような問題にも適用することができる。
x*の初期値をx0 = 0 とする。x*が二次形式

を最小化する一意な解であることに注意し、最初の基底ベクトルp1をx = x0でのfの勾配Ax0−b=−bとなるように取る。このとき、基底の他のベクトルは勾配に共役である。そこで、この方法を共役勾配法と呼ぶ[2][3][4]。
rkをkステップ目での残差

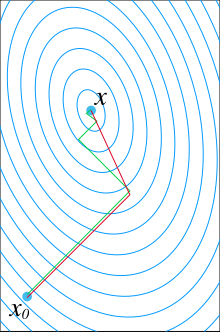
とする。rkはx = xkでのfの負の勾配であることに注意されたい。最急降下法はrkの方向に進む解法である。pkは互いに共役でなければならないので、rkに最も近い方向を共役性を満たすように取る。これは

のように表すことができる(記事冒頭の図を参照)。
アルゴリズム
以上の方法を簡素化することにより、Aが実対称正定値である場合にAx = bを解くための以下のアルゴリズムを得る[4]。初期ベクトルx0は近似解もしくは0とする。
for (k = 0; ; k++) if が十分に小さい then break 結果は









Octaveでの共役勾配法の記述例
Gnu Octaveで書くと以下のようになる。
function [x] = conjgrad(A,b,x0)
r = b - A*x0;
w = -r;
z = A*w;
a = (r'*w)/(w'*z);
x = x0 + a*w;
B = 0;
for i = 1:size(A)(1);
r = r - a*z;
if( norm(r) < 1e-10 )
break;
endif
B = (r'*z)/(w'*z);
w = -r + B*w;
z = A*w;
a = (r'*w)/(w'*z);
x = x + a*w;
end
end
前処理
前処理行列とは、Aと同値なP-1A (PT)-1の条件数がAより小さく、Ax=bよりP-1A (PT)-1 x′ =P-1b′の方が容易に解けるような正定値行列 P.PTを指す[4]。前処理行列の生成には、ヤコビ法、ガウス・ザイデル法、対称SOR法などが用いられる[15][16]。
最も単純な前処理行列は、Aの対角要素のみからなる対角行列である。これはヤコビ前処理または対角スケーリングとして知られている。対角行列は逆行列の計算が容易かつメモリも消費しない点で、入門用として優れた方法である。より洗練された方法では、κ(A)の減少による収束の高速化とP-1の計算に要する時間とのトレードオフを考えることになる。
正規方程式に対する共役勾配法
任意の実行列Aに対してATAは対称(半)正定値となるので、係数行列をATA、右辺をATbとする正規方程式を解くことにより、共役勾配法を任意のn×m行列に対して適用することができる(CGNR法[17])。
ATAx = ATb
反復法としては、ATAを明示的に保持する必要がなく、行列ベクトル積、転置行列ベクトル積を計算すればよいので、Aが疎行列である場合にはCGNR法は特に有効である。ただし、条件数κ(ATA)がκ(A2)に等しいことから収束は遅くなる傾向があり、前処理行列を使用するCGLS (Conjugate Gradient Least Squares[18])、LSQRなどの解法が提案されている。LSQRはAが悪条件である場合に最も数値的に安定な解法である[19][20]。
関連項目
- 双共役勾配法 (BICG)
- 非線形共役勾配法
脚注
[脚注の使い方]
出典
- ^ a b c 山本哲朗『数値解析入門』(増訂版)サイエンス社〈サイエンスライブラリ 現代数学への入門 14〉、2003年6月。ISBN 4-7819-1038-6。
- ^ a b c d e 森正武. 数値解析 第2版. 共立出版.
- ^ a b c d e 数値線形代数の数理とHPC, 櫻井鉄也, 松尾宇泰, 片桐孝洋編(シリーズ応用数理 / 日本応用数理学会監修, 第6巻)共立出版, 2018.8
- ^ a b c d e f g 皆本晃弥. (2005). UNIX & Informatioin Science-5 C 言語による数値計算入門.
- ^ 田端正久; 偏微分方程式の数値解析, 2010. 岩波書店.
- ^ 登坂宣好, & 大西和榮. (2003). 偏微分方程式の数値シミュレーション. 東京大学出版会.
- ^ Zworski, M. (2002). Numerical linear algebra and solvability of partial differential equations. Communications in mathematical physics, 229(2), 293-307.
- ^ Gill, P. E., Murray, W., & Wright, M. H. (1991). Numerical linear algebra and optimization (Vol. 1, p. 74). Redwood City, CA: Addison-Wesley.
- ^ Gilbert, J. C., & Nocedal, J. (1992). Global convergence properties of conjugate gradient methods for optimization. SIAM Journal on optimization, 2(1), 21-42.
- ^ Steihaug, T. (1983). The conjugate gradient method and trust regions in large scale optimization. SIAM Journal on Numerical Analysis, 20(3), 626-637.
- ^ Black, Noel and Moore, Shirley. "Biconjugate Gradient Method." From MathWorld--A Wolfram Web Resource, created by Eric W. Weisstein. mathworld
.wolfram .com /BiconjugateGradientMethod .html - ^ Dai, Y. H. (2010). Nonlinear conjugate gradient methods. Wiley Encyclopedia of Operations Research and Management Science.
- ^ Hager, W. W., & Zhang, H. (2006). A survey of nonlinear conjugate gradient methods. Pacific journal of Optimization, 2(1), 35-58.
- ^ Dai, Y., Han, J., Liu, G., Sun, D., Yin, H., & Yuan, Y. X. (2000). Convergence properties of nonlinear conjugate gradient methods. SIAM Journal on Optimization, 10(2), 345-358.
- ^ Eisenstat, S. C. (1981). Efficient implementation of a class of preconditioned conjugate gradient methods. SIAM Journal on Scientific and Statistical Computing, 2(1), 1-4.
- ^ Kaasschieter, E. F. (1988). Preconditioned conjugate gradients for solving singular systems. Journal of Computational and Applied Mathematics, 24(1-2), 265-275.
- ^ Black, Noel and Moore, Shirley. "Conjugate Gradient Method on the Normal Equations." From MathWorld--A Wolfram Web Resource, created by Eric W. Weisstein. mathworld
.wolfram .com /ConjugateGradientMethodontheNormalEquations .html - ^ Bjorck, A. (1996). Numerical methods for least squares problems (Vol. 51). SIAM.
- ^ Paige, C. and Saunders, M. "LSQR: An Algorithm for Sparse Linear Equations and Sparse Least Squares." ACM Trans. Math. Soft. 8, 43-71, 1982.
- ^ Paige, C. C., & Saunders, M. A. (1982). Algorithm 583: LSQR: Sparse linear equations and least squares problems. ACM Transactions on Mathematical Software (TOMS), 8(2), 195-209.
参考文献
- Hestenes, Magnus R.; Stiefel, Eduard (1952-12). “Methods of Conjugate Gradients for Solving Linear Systems”. Journal of Research of the National Bureau of Standards 49 (6). http://nvl.nist.gov/pub/nistpubs/jres/049/6/V49.N06.A08.pdf.
- Atkinson, Kendell A. (1988). “Section 8.9”. An introduction to numerical analysis (2nd ed.). John Wiley and Sons. ISBN 0-471-50023-2
- Avriel, Mordecai (2003). Nonlinear Programming: Analysis and Methods.. Dover Publishing.. ISBN 0-486-43227-0
- Golub, Gene H.; Van Loan, Charles F. (1996). “Chapter 10”. Matrix computations (2nd ed.). Johns Hopkins University Press.. ISBN 0-8018-5414-8
- Meurant, Gerard; Tichy, Petr (2024). Error Norm Estimation in the Conjugate Gradient Algorithm. SIAM. ISBN 978-1-61197-785-1
外部リンク
- Conjugate Gradient Method by Nadir Soualem.
- Preconditioned conjugate gradient method by Nadir Soualem.
- An Introduction to the Conjugate Gradient Method Without the Agonizing Pain by Jonathan Richard Shewchuk.
- Iterative methods for sparse linear systems by Yousef Saad
- LSQR: Sparse Equations and Least Squares by Christopher Paige and Michael Saunders.
| |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 連立一次方程式 | |||||||||||
| ベクトル | |||||||||||
| ベクトル空間 | |||||||||||
| 計量ベクトル空間 | |||||||||||
| 行列・線型写像 |
| ||||||||||
| 行列式 | |||||||||||
| 多重線型代数 | |||||||||||
| 数値線形代数 |
| ||||||||||
| 行列値関数 | |||||||||||
| その他 | |||||||||||
| | |||||||||||
| ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 非線形(無制約) |
|  | ||||||||||||
| 非線形(制約付き) |
| |||||||||||||
| 凸最適化 |
| |||||||||||||
| 組合せ最適化 |
| |||||||||||||
| メタヒューリスティクス | ||||||||||||||
| ||||||||||||||
典拠管理データベース | |
|---|---|
| 全般 |
|
| 国立図書館 |
|
| その他 |
|







